
ThinkX株式会社は2017年からニューラルネットワークによるEnd to End音声合成モデルを研究、バージョンアップを経て、テキストを高速に高品質な音声波形で読み上げる音声合成AIシステム「NeuraVoice2 β」を開発したことを発表した。
高速・高品質な音声波形で読み上げる「NeuraVoice2 β」
音声は生命が陸に上がり聴覚、そして喉頭を発達させて以来、やがて主要なコミュニケーション手段として機能してきた。コンピューティングの高度化に伴い、聴覚や音声による情報処理は、今後活用の幅が爆発的に広がることが予想され、大きなポテンシャルを秘めている。先端情報テクノロジー企業ThinkX(旧6th Sense)は、リアルタイム性能を示す指標であるRTF(Real Time Factor)0.01~1.0で高速に動作するテキストからの音声合成システム「NeuraVoice2 β」を開発した。

・RTF(Real Time Factor) 0.01~1.1未満*の高速で高品質な音声合成。
・1000兆桁までの数字の正確な読み、上付き文字等の特殊な表記の読みが可能。
・発話速度や音高、強さを調節可能。
・ステミング(語幹)への変換、記号を読むかどうか、ストップワードを排除しキーワードのみ読み上げる、など高度な設定が可能。
・ほぼ同一のアルゴリズムで複数言語への拡張が可能。
・独自の学習データを用意することで、任意の話者の声や特定の語群を強化した音声を合成可能。
*0.01~1.1未満
【GPU】
RTF(Real Time Factor) 平均 0.0227
機種:NVIDIA GTX1080Ti x 1
計測方法:10のランダムに抽出した短長様々なテキストからのベンチマークテスト
【CPU】
RTF(Real Time Factor) 平均 1.1106
機種:Intel Core i9 2.9GHz
計測方法:10のランダムに抽出した短長様々なテキストからのベンチマークテスト
ThinkX株式会社の取り組みと「NeuraVoice2 β」
2015年より機械学習をはじめとする先端情報技術(AI)を研究開発してきたThinkX,Inc(旧6th Sense,Ltd)は、2017年より大塚一輝氏と園部良介氏でニューラルネットによるEnd To End音声合成技術の研究を開始(園部氏はその後標準的な日本語音声合成データセットとなるJSUTを東京大学猿渡研究室で開発)、Bi-LSTM CRM Entity Recognitionによる音素時間予測モデルやフジサキモデルを基礎とする確率的イントネーション包絡予測モデルなどの研究開発を行なってきた。
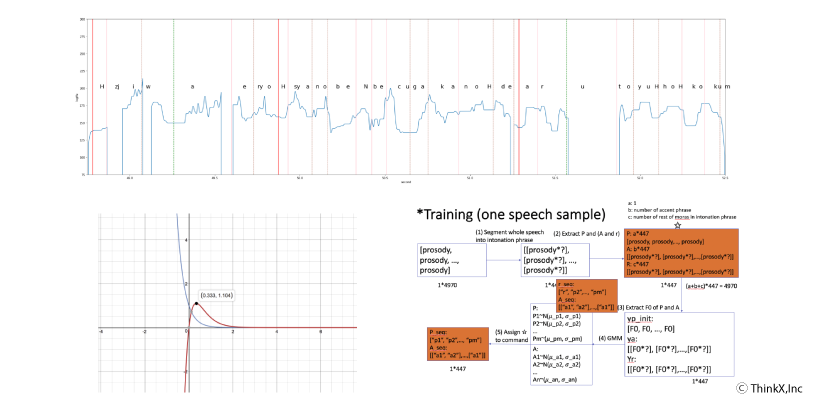
2018年にはリアルタイム性能を超えるEnd to End TTSの実現のため、独自にMel周波数スペクトルの中間表現を用いる並列波形シグナル生成手法を模索、NeuraVoice1では混合ガウスモデルによるAttentionメカニズムからのMel Spectrogram生成エンコーダー/デコーダーを開発してきたが、期待する性能を実現できなかった。
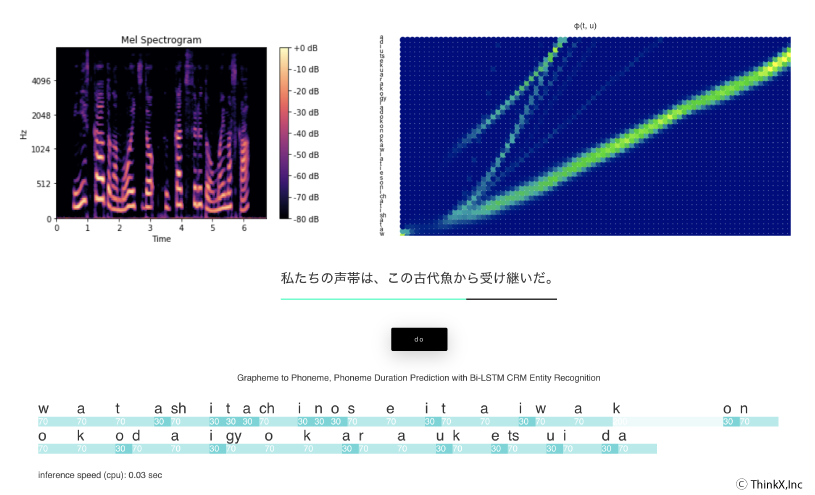
今回のバージョン「NeuraVoice2 β」では中間表現生成のためのエンコーダー/デコーダーにTransformerが用いられ、速度と合成品質を両立させる高い性能を実現。現在、英語と日本語に対応しているが、多言語拡張が比較的容易なため、近々中国語、韓国語、スペイン語などの言語にも対応予定。特に日本語についてはデータセットの強化を進め、学習データを増やすことで合成品質が向上することから、より広範な語彙で自然な発話が可能になる。
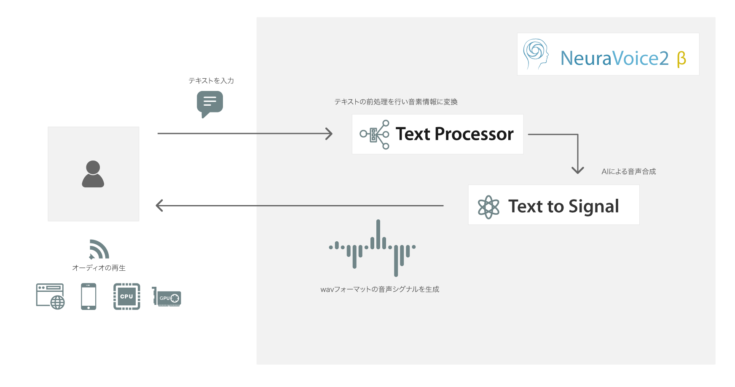
「NeuraVoice2 β」はThinkXで開発を進めている音声ガイドシステムCITYWALKの時期バージョンに用いられる他、特に通信環境の限定されるエッジデバイス等での状況に応じた高速な音声合成を必要とする顧客ニーズを中心に提供予定。
【動画】
ThinkX株式会社



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
山田 航也PR







このカテゴリの新着記事

注目のロボット









注目のロボット企業







連載・コラム

