
女子高生チャットボット「りんな」の開発で知られるMicrosoftのAI&リサーチ部門のAIチャットボットの研究チームが、2020年6月にスピンアウトして設立したAI開発企業がrinna株式会社だ。同社は2021年4月に日本語に特化した中規模サイズの「GPT-2」(GPT2-medium)を公開して反響を呼んだ。そして、同年8月25日、製品開発のための実験過程で、日本語に特化した「GPT-2」と、世界的に衝撃を与えた「BERT」の事前学習モデルの、サイズが異なる2つのGPT-2(GPT2-small, GPT2-xsmall)を開発したことを発表した。
日本語の自然言語処理(NLP)の研究・開発コミュニティに貢献するために、開発した事前学習モデルとその学習を再現するためのソースコードを、GitHubおよびNLPモデルライブラリHuggingFaceにMITライセンスのオープンソースとして公開するとした。
さらに、GPT-2に加え、BERTを改良したモデルであるRoBERTaも公開。 GPT-2とBERTの公開により利用者は目的に合わせたモデル選択や、追加学習により多様なタスクへの応用が可能となった。
【日本語GPT-2の機能】GPT2-small, GPT2-xsmall
言語モデルは、会話や文章の「人間が使う言葉」を確率としてモデル化している。優れた言語モデルとは、確率を正確に推定できるものを指しており、例えば、 “確率(吾輩は猫である)>確率(吾輩が猫である)” と推定できるのが、言語モデルの能力だ。GPT-2は、単語の確率の組み合わせから文の確率を計算する言語モデルで、 “確率(吾輩は猫である)=確率(吾輩)×確率(は|吾輩)×確率(猫|吾輩,は)×確率(で|吾輩,は,猫)×確率(ある|吾輩,は,猫,で)” のような方法で推定を行う。この性質を用いて、GPT-2は「吾輩は」という単語を入力したとき、次にくる単語として確率が高い「猫」を予測することができる。
今回、同社が公開した日本語GPT-2は、一般的な日本語テキストの特徴を有した高度な日本語文章を自動生成する。例えば「本日はご参加ありがとうございました。誰も到達していない人工知能の高みへ、ともに」という講演後のメールを想定した文章をGPT-2に入力として続きの文章を自動生成すると、入力文章の文脈を考慮した文章が生成される。
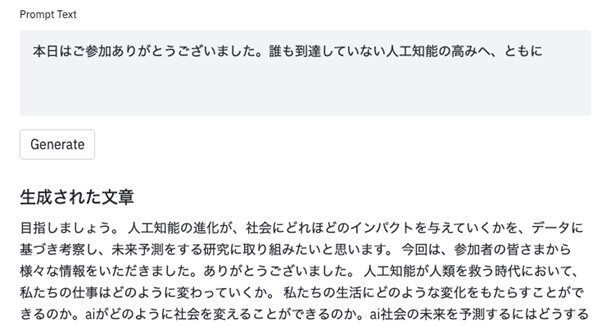
なお、今回展開するモデルサイズの違いはパフォーマンスとコストのトレードオフであり、研究者や開発者が最善のモデル選択をすることが可能となる。また、GPT2-mediumも、学習データと学習時間を増やし、より高性能なモデルへとアップデートされている。
【日本語BERTの機能】BERTを改良したモデルであるRoBERTa
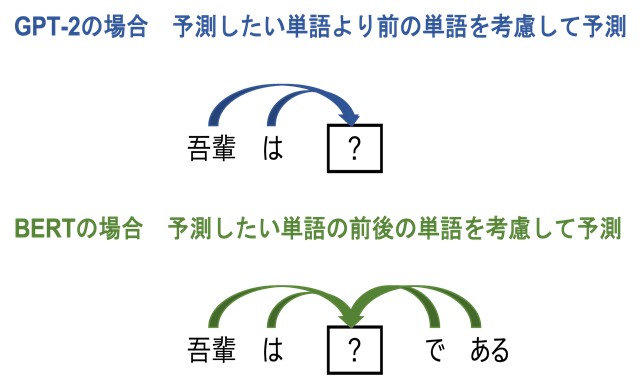
GPT-2は、予測したい単語より前の単語を考慮して次の単語を予測する言語モデルだ。これに対してBERTは、予測したい単語の前の単語だけでなく後の単語も考慮して予測を行う。GPT-2では「吾輩」「は」を考慮して「猫」を予測しますが、BERTでは前の単語「吾輩」「は」と後ろの単語「で」「ある」を考慮して「猫」を予測する。
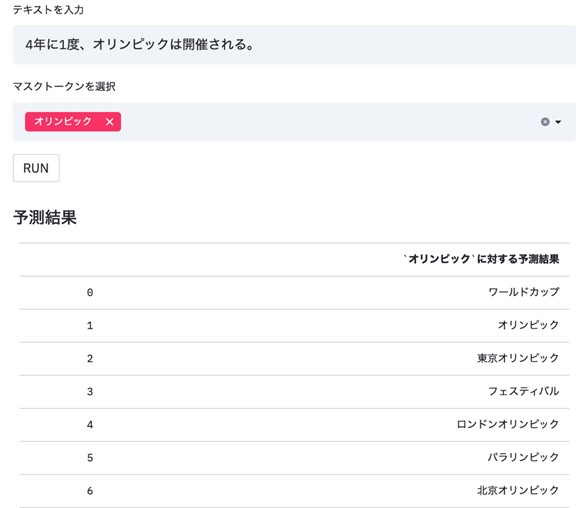
今回公開するRoBERTaは、BERTを改良したモデルであり、BERTより高い性能が報告されている。RoBERTaを用いて「4年に1度、[MASK]は開催される。」の[MASK]部分を予測すると、オリンピックやワールドカップといった4年に1度開催されるイベントが上位に予測される。
文章生成タスクにおいては、文章を1単語ずつ順次予測するGPT-2が主流だが、文章分類タスクなどの文章全体を考慮したタスクにおいては、BERTがよく用いられる。文章分類タスクの他にも、質問応答タスクや固有表現認識タスクなど多様なタスクに適用することが可能だ。
同社の日本語事前学習モデルの特徴
rinna社の日本語事前学習モデルは、学習データとして、日本語CC-100と日本語Wikipediaの計75ギガバイトのオープンソースデータを使用。8つのNVIDIA Tesla V100 GPUを用いて、75ギガバイトの日本語テキストを最大45日間かけ学習し、すべてのモデルにおいて十分に学習された汎用性がある。なお、学習された事前学習モデルはHuggingFaceにMITライセンスで公開されており、事前学習モデルの学習に用いたソースコードはGitHubにMITライセンスで公開されている。利用者は、日本語CC-100とWikipediaのオープンソースデータを用いることで、自分のマシンで同社の結果を再現可能だ。
また、モデルサイズが異なるGPT2-medium(3.36億パラメータ)、GPT2-small(1.10億パラメータ)、GPT2-xsmall(0.37億パラメータ)の3つのモデルを公開しており、加えて、BERTを改良したRoBERTa(1.10億パラメータ)も公開しており、利用者は目的に合わせたモデルを選択することができる。
今後の展開
同社の研究チームが開発する大規模な事前学習モデルは、すでに同社製品に広く利用されており、今後も、AIに関する研究を続け、高性能な製品を開発していくと述べている。また、研究・開発コミュニティに貢献するために、研究成果を公開していく予定だ。さらに、他社との協業も進めることで、AIの社会実装の拡大を目指すと述べている。
GitHub:https://github.com/rinnakk/japanese-pretrained-models
rinna株式会社



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
ロボスタ編集部PR







このカテゴリの新着記事

注目のロボット









注目のロボット企業







連載・コラム

