
NVIDIAは業界のベンチマークグループであるMLPerfの推論テストにおいて、x86コンピューターだけでなくArmでも性能とエネルギー効率において高い水準を記録したことを発表した。MLCommonsでの推論テストにおいて、NVIDIAが性能とエネルギー効率で新記録を樹立するのはこれで3回連続。また、データセンターカテゴリーでは初めてArmベースのシステムを使ってテストを行い、今日における最も革新的なテクノロジであるAIの導入方法について、ユーザーの選択肢をさらに広げた。
テストの結果
推論テストではNVIDIAからのシステムに加え、Alibaba、Dell Technologies、富士通、GIGABYTE、HewlettPackard Enterprise、Inspur、Lenovo、Nettrix、Supermicro を含む NVIDIA のエコシステムパートナー9社のシステムによるテスト結果が提出され、NVIDIA AIプラットフォームを搭載したシステムは、直近の7つの推論の性能テストすべてで最高の成績を収めた。
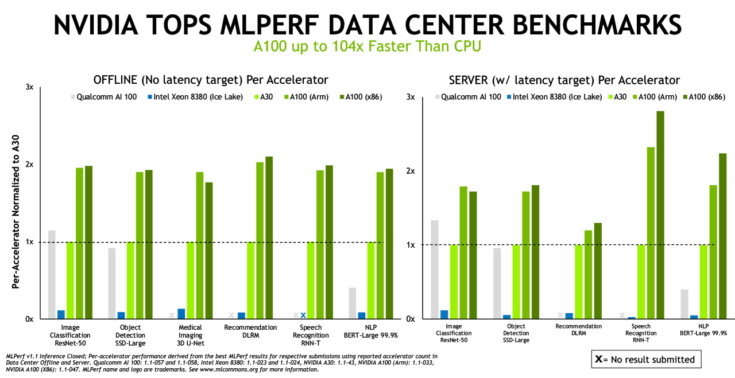
推論はコンピューターがAIソフトウェアを実行して、物体の認識や予測をするときに行われるもの。このプロセスではディープラーニングのモデルを使って、データのフィルタリングが行われ、人間ではなし得ない成果が導き出される。MLPerfの推論ベンチマークは今日最も需要が高いAIのワークロードとシナリオに基づいたもので、コンピューター ビジョン、医用画像、自然言語処理、レコメンダー システム、強化学習などが対象となっている。そのため、どのようなAIアプリケーションを導入する場合でも、ユーザーはNVIDIAのテクノロジによって、それぞれの新記録を樹立できる。
AIモデルとデータセットは成長を続け、AIのユースケースはデータセンターからエッジ、およびその先にまで拡大している。そのため、ユーザーは安心かつ柔軟に導入できる性能を求めている。MLPerfはユーザーが確信を持って購入の判断を下すための情報を提供する。なお、MLPerfはAlibaba、Arm、Baidu、Google、IntelおよびNVIDIAをはじめとする業界の数十のリーダー企業から支持されている。
Armベースのサーバーがx86ベースのサーバーにほぼ匹敵する
Armアーキテクチャは世界中のデータセンターで導入が進んでいる。その主な理由としてはエネルギー効率の良さ、性能の向上、ならびにソフトウェア エコシステムの拡大がある。最新のベンチマークではGPUアクセラレーテッドプラットフォームとしてのAmpere Altra CPUを搭載したArmベースのサーバーが、同じような構成のx86ベースのサーバーにほぼ匹敵する性能をAI推論の処理で発揮できることが示されている。実際、テストの1つで、Armベースのサーバーが同様の構成のx86システムを上回る性能を発揮した。
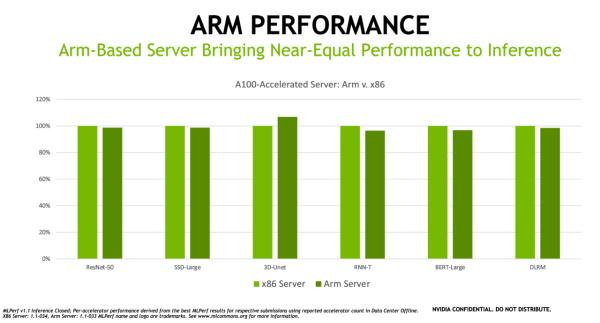
NVIDIAは「あらゆるCPUアーキテクチャに対応してきた長い実績があり、同業者が審査を行うベンチマークでArmがAIの優れた能力を示したことは誇らしく思います。」としている。
ArmのHPCおよびツール部門のシニアディレクターであるデイビッド ルコンマー(David Lecomber)氏は、次のように述べている。
NVIDIAのパートナーもAIパワーを実証
NVIDIAのAIテクノロジは、拡大を続ける大規模なエコシステムから支持されている。直近のベンチマークでは7つのOEM企業が、合計22のGPUアクセラレーテッド プラットフォームを活用したテスト結果を提出している。これらのサーバーモデルのほとんどはNVIDIAによって認証されたシステムであり、多様なアクセラレーテッドワークロードを実行するための検証を受けている。また、それらの多くは、先月公式にリリースされたソフトウェアである、NVIDIA AI Enterpriseに対応している。なお、今回のベンチマークに参加したNVIDIAのパートナーには、Dell Technologies、富士通、HewlettPackard Enterprise、Inspur、Lenovo、NettrixおよびSupermicroなどのメーカー、ならびにクラウドサービスプロバイダーのAlibabaがある。
NVIDIAのAIが成功を収めている主な理由
あらゆるユースケースでNVIDIAのAIが成功を収めている主な理由の1つは、フルスタックのソフトウェアにある。たとえば推論では、多様なユースケースを想定したトレーニング済みのAIモデルを提供している。NVIDIATAO Toolkitを使えば転移学習を使用して、特定のアプリケーションのために、これらのモデルをカスタマイズすることができる。また、NVIDIA TensorRT ソフトウェアによって、メモリを効率よく活用し、より速く動作するようにAIモデルを最適化することができる。
NVIDIAはMLPerfのテストでこのソフトウェアをつねに使用し、x86とArmベースのシステムのどちらでも、このソフトウェアは利用できる。また、これらのベンチマークでは、NVIDIA Triton Inference ServerソフトウェアとMulti-Instance GPU(MIG)機能も採用した。これらのソフトウェアと機能により、あらゆる開発者が通常はコードに関するエキスパートを必要とするような性能を得られるようになる。このソフトウェアスタックの継続的な改善が功を奏し、NVIDIAはわずか4か月前に行われた前回のMLPerf推論ベンチマークに比べて、性能を20%、エネルギー効率を15%向上させることができた。
直近のテストで使用されたすべてのソフトウェアはMLPerfのリポジトリで入手できるので、誰でもベンチマークでの結果を再現することができる。NVIDIAではGPUアプリケーションのためのソフトウェアハブであるNGCで利用できる、ディープラーニングのフレームワークとコンテナに、このようなコードを継続的に追加している。これらはフルスタックのAI機能の一部であり、すべての主要なプロセッサ アーキテクチャに対応しており、最新の業界ベンチマークで実証されている。
世界のコンピューターメーカーがNVIDIA AIを活用し、MLPerfで圧倒的な記録を達成 パフォーマンスは最大で3.5倍に向上
NVIDIAがデータセンターからエッジまで高速性能の記録を更新 A100/A30/A10、Jetsonの「MLPerf」他社比較ベンチ結果を公表
「NVIDIA A100」GPUがベンチマークの最速記録を更新 CPUより最大237倍も高速なAI推論を達成 「MLPerf」6応用分野で圧勝
NVIDIA関連記事



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
山田 航也PR







このカテゴリの新着記事

注目のロボット









注目のロボット企業







連載・コラム

