
NVIDIA(エヌビディア)が2016年10月7日に開催した「GTC Japan 2016」には超満員の来場者が詰めかけた。それはディープラーニング全盛の時代にNVIDIAが注目されていることを示すのには十分な混雑ぶりだった。
そしてそのイベントの基調講演で同社の社長兼CEOのジェンスン・ファン氏は、ディープラーニングが医療や交通など多くの分野に革命的な変革をもたらそうとしていると語り、更に「NVIDIAは、ビジュアルコンピューティング・カンパニーから”AIコンピューティング・カンパニー”へと変革する」ことを高らかに宣言した。
なぜディープラーニングでNVIDIAがこれほどまでに注目されるのか?
AIコンピューティングを宣言する技術的アドバンテージはどこにあるのか?
ポイントをわかりやすく解説したい。

自作パソコンに興味がある人を除くと「NVIDIA」(エヌビディア)という名前を知っている一般の消費者は意外と少ないかも知れない。
同社は半導体メーカーだ。最も有名な商品は「GeForce」シリーズのビデオカードだ(あるいはワークステーション向けのQuadroやスーパーコンピュータ向けのTeslaを耳にしたことがあるかもしれない)。いわゆるグラフィック技術「GPU」(グラフィックス・プロセッシング・ユニット)でリードし、ビジュアルコンピュータティングの世界では屈指の知名度を持つ企業だ。
グラフィックスの覇者がディープラーニングの覇者も目指す理由
NVIDIAが「AIコンピューティング」を標榜するには明確な理由がある。ディープラーニングには膨大な「行列演算」処理が必要となる。グラフィックスで培ってきた行列演算の処理技術と同じだ。
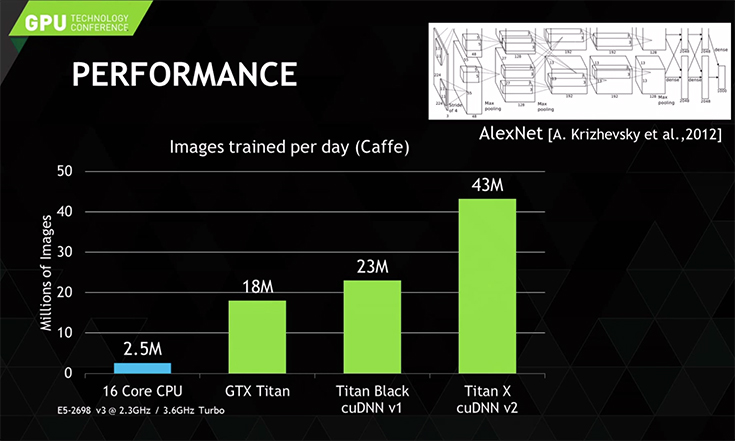
パソコン等で頭脳を担ってきたCPUに比べて、高度なグラフィック演算のために開発された「GPU」は行列演算の処理速度がおおまかな目安でCPUの10倍以上、はるかに高速化されるとしている。
従来は高速なグラフィック処理をCPU(中央演算装置)から分離してGPUに担当させることで描画やCG処理を高速化したように、ディープラーニングに関わる膨大な処理負担をCPUから分離してGPUに担当されることで高速化をはかるアーキテクチュアだ。CPUではデュアル(2個)コア、クアッド(4個)コアといった表現が用いられるが、GPUはこのコアに相当するものが数千の単位で構成されていることでも構成上のちがいが理解できるだろう。
更にGPUはスケーラブル性に富んでいる。すなわち、必要に応じて複数のGPUを増設することで、行列演算に関わる処理速度の能力を格段にアップさせることができる。
言い換えれば、企業がディープラーニングのシステムを開発したり、導入しようとする際、従来であればディープラーニングで機械学習を行う「トレーニング」に関わる演算時間に膨大な時間が必要となり、その結果、実用的にはスーパーコンピュータ級のシステムが必須と思われていた。
そこに切り込んだのがGPUコンピューティングだ。CPUと比較して、はるかに行列演算には強いGPUを活用することで、比較的安価で手軽なのに高速なディープラーニング・システムの構築が可能になる。
ディープラーニングに必要なライブラリを提供
更に、企業にとってもうひとつの課題はソフトウェア開発だ。実際にディープラーニングのフレームワークを構築するためにはアルゴリズムを熟知することは大変な作業で、開発にはエンジニアの育成などを含めて膨大なコストが伴うと考えがちだ。しかし、現状では「Caffe」や「Theano」「Torch」「Minerva」など、比較的誰でも利用できるディープラーニング・ライブラリやディープラーニング・フレームワークが手軽に入手でき、自社のシステム開発に組み込むことができる。また、これらのライブラリはGPUを活用して高速にマッピングしたり演算処理を行うように作られている。そして更に、この橋渡しを行うライブラリ「cuBLAS」や「cuDNN」をNVIDIAが提供することでほとんどのプラットフォームで、かつほとんどの処理で開発者はGPUコードを書く手間なく、ディープラーニングのシステムが開発できるようになった。つまり、開発ツール環境が整備されているのである。
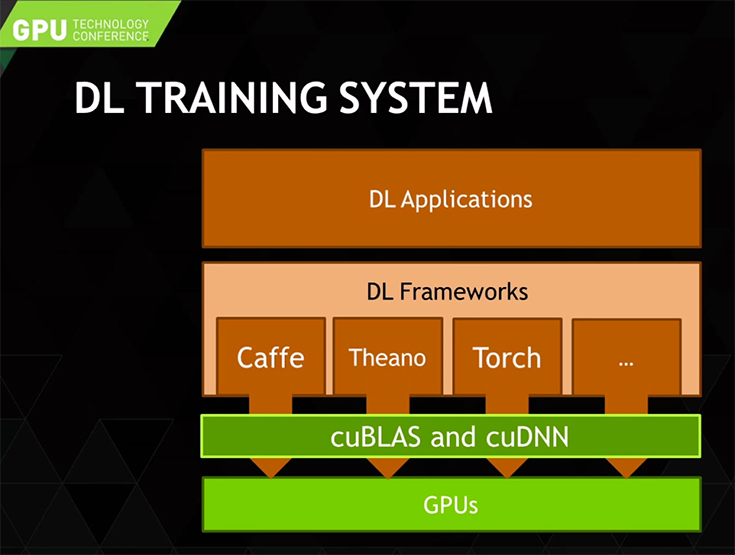
NVIDIAが提供するこれらのライブラリや、GPU向けにC言語の統合開発環境が「CUDA」(クーダ)だ。開発者が比較的簡単にディープ・ニューラル・ネットワークを活用したシステムを構築できるハードウェアとソフトウェア環境を提供しているため、これほどまでに開発者が注目するベンダーとなっている。
自動運転車やロボットにもディープラーニングを展開
自動運転やロボットでディープニューラルネットワークを使いたいと考える開発者にはボード型コンピュータで応えようとしている。
NVIDIAは自動運転車両に組み込む自動運転車向け AI 車載コンピュータ「NVIDIA DRIVE PX2」を発表。オートクルーズから完全自動運転までを同一のアーキテクチュアでスケーラブルに提供していく。更に自社開発で自動運転用OS「DRIVEWORKS」を開発し、乗用車やトラック、シャトルなどのAIトランスポーテーションの構築を考えているメーカーや地方公共団体等に提供していくことで1000兆円産業を創出する考えだ。

自動運転車についてはNVIDIAはディープ ニューラル ネットワークを利用した自律走行車用プラットフォーム「Cloud-to-Car」の共同開発でBaidu(百度)との提携を発表している。Baiduは主に地図(マッピング)情報やクラウド技術を提供し、NVIDIAの自動走行車用コンピューティングと融合させる計画だ。
また、10月24日、テスラモーターズは今後、すべてのテスラ車両(Model S、Model X、発売予定のModel 3)に、完全な自動運転機能を提供できる車載「スーパーコンピュータ」を装備すると発表。このスーパーコンピュータには「NVIDIA DRIVE PX 2」 AIコンピューティング・プラットフォームが搭載される(詳しくは既報「テスラモーターズが「NVIDIA DRIVE PX 2」を採用 完全な自動運転機能の実現に向けて」)。
更にロボット等に組込できる「NVIDIA Jetson」開発キットも販売。既に、サイバーダインやトヨタ自動車、アクティブリンクなど、多くの企業がロボットに採用している。



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
神崎 洋治PR







このカテゴリの新着記事

注目のロボット









注目のロボット企業







連載・コラム

