
2月10日(水)、六本木ヒルズのGoogle本社にて、「第2回TensorFlow勉強会」が開催されました。Google本社に集まったエンジニアは約150名。人工知能を研究している方をはじめ、ロボット業界からも多くの関係者が参加しました。

司会はKUNOの佐藤さんと、

OYOYO PROJECTやまうちさんがプログラムを組んだ、ロボットスタートのPepperが行いました。果たしてどのようなイベントになったのでしょうか?

とイベントレポートのその前に。さて、こちらの写真は、イベントに登壇した弱冠25歳の若者が、当日行った会話エンジンのデモの様子です。一見すると全く会話になっていないように思えますが、こちらはなんとTensorFlowを用いて数日のうちに作り上げたものというから驚きです。詳しくは後述しますが、「おはようございます」という発言に対して、「おはよう ござい ござい ます!」と返事をしています。たった数日で会話らしきものを作れてしまうとは、一体TensorFlowとはどのようなものなのでしょうか。また、それを作った若者とは? 早速見ていきましょう。
About Google & TensorFlow by 佐藤一憲さん

まずはじめにGoogle Staff Developer Advocate の佐藤一憲さんから、GoogleとTensor Flowについての紹介です。

TensorFlowは、2015年11月9日にGoogleが無償でソースコードを公開したディープラーニングをおこなうことができる機械学習システム。こちらはオープンソースとしてリリースされました。
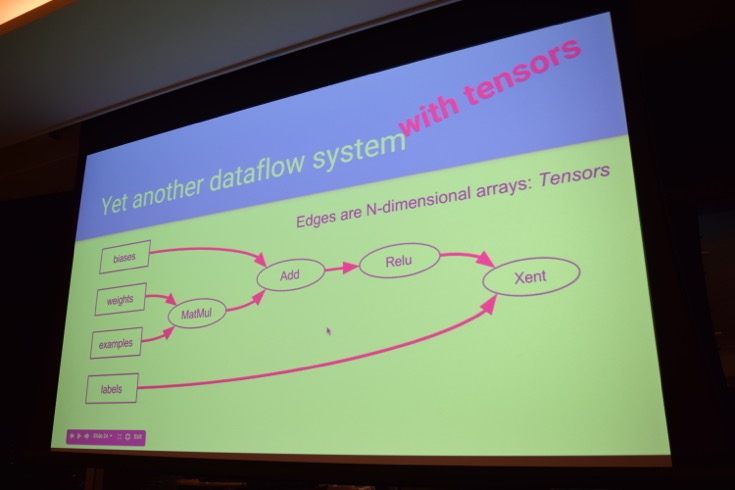
Google社内のマシーンラーニングエンジニアもバリバリ使っているという「TensorFlow」。TensorFlowには、ディープラーニングやマシーンラーニングの使いやすいライブラリが整ってはいるものの、それらに特化したフレームワークではなく、多次元配列に入る数字を非常に高速に計算するための汎用のHPCフレームワークとしても使うことができます。

佐藤さんはディープラーニングについて、「プログラマーが考えるのではなく、コンピューターに考えさせるという点が非常に画期的なところです」と述べました。

TensorFlowを使えば、上の画像のような簡単なプログラムを書くだけで、手書き数字をかなりの精度で認識するようになります(発表されたものでは91%の確率で正答)。
また、TensorFlowには、ビジュアライゼーションツールがあるため、結果を視覚的・直感的に判断することができます。佐藤さんは最後に「ご興味がある方は、これを機にTensorFlowを是非使ってみてください」と会場に集まったエンジニアの皆さんに呼びかけました。
カーリングの局面評価関数を学習 by @CUTE_NA_CATさん

続いて、ゲームAIを研究しているという@CUTE_NA_CATさんの発表。@CUTE_NA_CATさんは、スポーツのカーリングのAIをTensorFlowで作ったそうです。

カーリングは、先攻・後攻に分かれて行うスポーツ、つまり完全情報のゲームであり、かつ、将棋や囲碁のような偶然がないゲームとは逆の “偶然をはらんだ” 不確定ゲームです。一方が得点を重ねると一方が失点するというゼロサムの要素も持っており、「ゼロサムの完全情報不確定ゲーム」と考えられます。ここで、”カーリングというスポーツのルールは教えずに” TensorFlowに、局面の画像を読み込ませていきます。

線形関数や、CNN(Convolutional Neural Network)など様々な方法でカーリングの評価関数を学習させようと試みましたが、結果はまだ納得がいくものではなかったようで、もっとモデルの精度を上げることができるのではないかとご自身で考察されていました。

@CUTE_NA_CATさんは「カーリングと機械学習の相性は良い」とし、機械学習の標準問題としてカーリングを活用することをお勧めしていました。
TensorFlow研究会について by 山下大輔さん

続いて、TensorFlow研究会の主催者山下大輔さんからのLT。山下大輔さんからは、前回の第一回TensorFlow勉強会の翌日に行われた研究会の内容の共有がありました。

研究会の参加者は約130名。そこでは、「TensorFlow独自の使い方はあまり見えていない感じだった」と感想をお話されました。様々なところで勉強会が開かれているTensorFlow。注目度の高さが伺えます。山下さんご自身はゲームのエンジニアということで、TensorFlow × ゲームAIということにも興味を持たれていました。
TensorFlowで会話AIを作ってみた by 新村拓也

最後に「TensorFlowで会話AIを作ってみた」という題目での発表。本記事の冒頭でご紹介したデモの会話エンジンを作った、1990年鹿児島生まれの、シーエイトラボ株式会社代表取締役 新村拓也さんのLTです。

まずは、今世の中に出回っている会話AIの紹介から。会話AIは、LINEやTwitterなどのチャットロボットに活用されていたり、ゲームのNPCなどにも活用されています。また会話エンジンを用いた雑談APIなども存在しており、有名なところでは「うずら」「もずく」「りんな」などがあります。
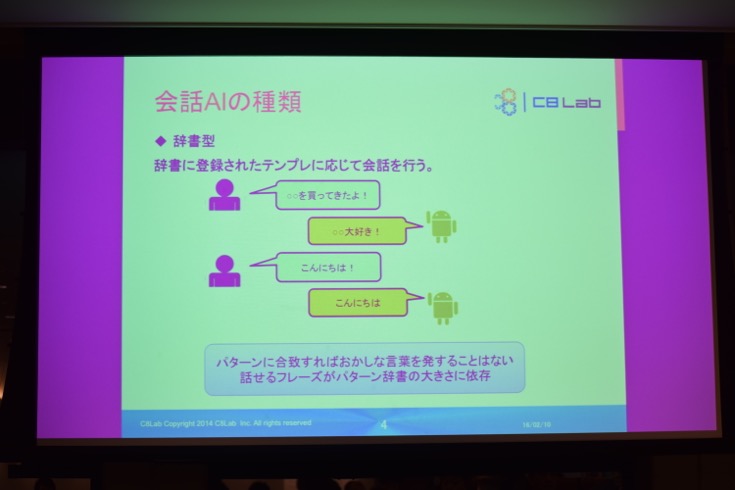
会話AIには、テンプレに応じた会話を行う「辞書型」と呼ばれるものや、
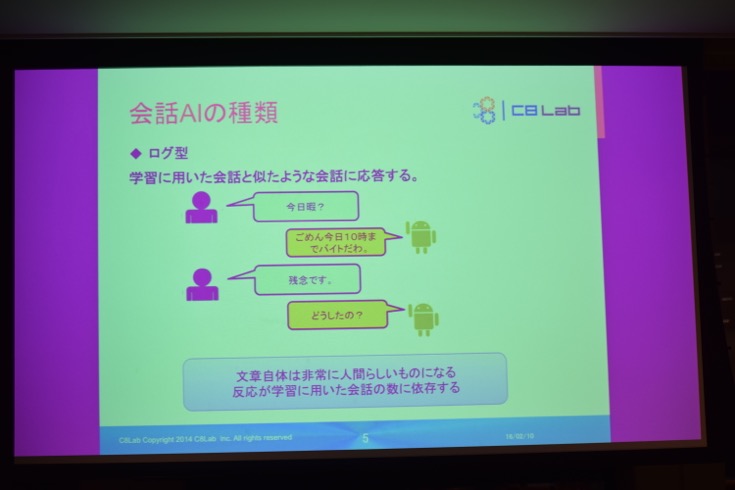
学習に用いた会話と似たような会話を展開していく「ログ型」と呼ばれるもの、

そして、出現した単語の “次に最も出現しそうな単語” で文章を生成していく「マルコフ型」と呼ばれるものなどがあります。これらは一般的に「人工無能」と言われており、AI自体はスポーツや野球といった単語の意味はわかっていません。
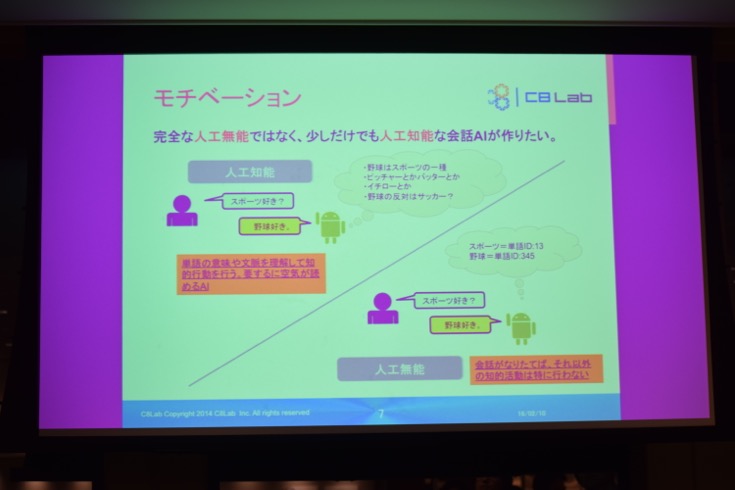
新村さんは、「会話が成り立てば、それ以外の知的行動は特に行わない “人工無能”ではなく、少しでも単語の意味や文脈を理解して知的行動を行う、空気を読むことができる “人工知能”」を持った会話AIを作りたい、というモチベーションで今回の会話AIを作られたそうです。

今回作った会話AIでは、単語を文字列でたくさん集め、会話の中で次に来る単語を予測するという「ニューラル言語モデル」を用いることで、各単語にベクトルを割り当てていきます。これによって、ベクトル演算で、「犬」と「猫」が近しいかどうかを判定でき、また、「王様 – 男性 + 女性 = 女王様」というベクトル演算が可能になります。
このように、ニューラル言語モデルを用いることで、単語に対して意味をもたせてあげるというのが今回の会話AIの一つ目の特徴です。
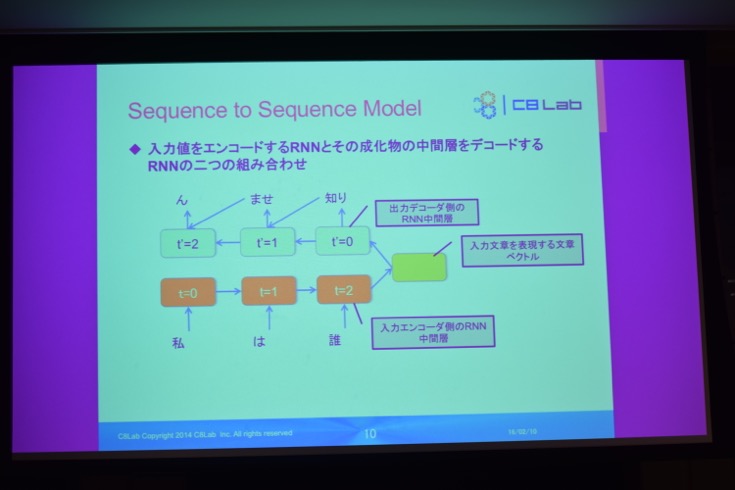
2つ目の特徴として、会話構築に「Sequence to Sequence Model」を使用したことが挙げられました。こちらは、TensorFlowのチュートリアルにて、英語をフランス語に翻訳するという内容で提供されているもの。これにより「言葉をモデル化して時系列で表すことが可能になった」と新村さん。
「Sequence to Sequence Model」は、時系列を扱うことができます。こちらを用いることで一個前の形態素の時間の状態をパラメータとして引き継いでいくことができるため、意味の通った会話文を構築することができます。

学習データには、Twitterのツイートやリプライのデータを約40,000セット使用しています。形態素解析にはMeCabを使用し、ユーザ辞書などのチューニングなどは行わずに進めていきました。形態素解析した結果、語彙数は約28,000語だったということ。新村さんは「会話AIを作るには非常に少ない語彙数だった」と振り返ります。
成長の記録
さて、ここからが本イベントのハイライト。新村さんが作った会話エンジンの成長の記録です。ディープラーニングにより、PCを開いている間、会話AIが自分で学習していきます。
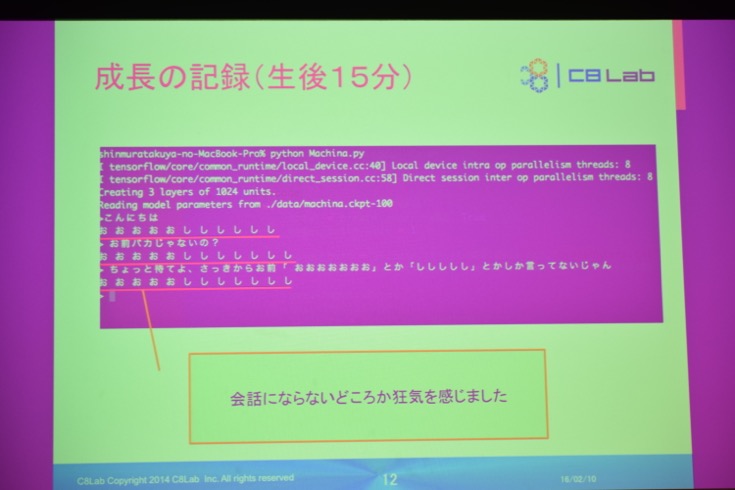
行頭が「>」の行は人側の入力で、行頭に何もない行がコンピューター側の発言です。設定が終わって15分後には、まだきちんとした反応が返ってきません。

一時間後でもまだ会話には程遠い状態です。むしろ15分前よりも変な文字列が出現しています。ただその中に「それ」という単語らしきものが出現しています。

単語が繰り返しになっていたり、文末に変な顔文字のような文字列が出現していますが、それでも挨拶が成立しています。素晴らしい成長ぶり。

眠い寝るお腹すいたって…。だいぶワガママになってきました。この辺りから可愛く見えてきました。

こんにちは、と言うと、「用事はにに?」と惜しい感じで聞き返してきています。すごい!

3日後になると、こんにちはという単語に対して、こんにちはと挨拶を返した後、ご用事はなぁに?と敬語も交えて返答しています。
デモ
ここからは、新村さんが発表中に行ったデモの内容です。その場でキーボードで入力するとすぐに返事が返ってきます。
>こんばんは
すいません!!!は まし まし ます ます
なぜか謝りました
>寝てた?
え?? ??
>とぼけないでください
ん!! です です です!
寝てたようです
>おはようございます
おはよう ござい ござい ます(!!!!!
>こんにちは
こんにちは! ご用事はなぁに?
>何か喋ってください
ん??? わからない わからない?
>おやすみなさい
おやすみのおっおっおっおっよろしく!!
最後に、みなさんによろしくとのことです。

新村さんは、「こんにちは」「こんばんは」という一言一言がTwitterで扱っているデータよりも短かったことが一つ目の問題だったと考察しました。
また、英語では25,000語〜30,000語扱えれば良いが、日本語は様々な表現があるので、50,000語は必要と言われている中、28,000語というデータの語彙数が少なかったことも課題に挙げました。
そして、金曜に完成して、3日間くらいフルで学習させて今の状態になったということについて、「再帰的ニューラルネットワークは収束速度が遅かった」と振り返りました。
今回の感想について「結局人工知能を作ろうと思ったが、会話生成の手法は人工無能のままでした。同じインプットに対して同じ回答を返すようなものです。ただ、単語の意味の獲得を後ろで行おうとしていたという点で、多少は人工知能の要素を組み込むことができたかもしれません。TensorFlowでよかったのは、ソースコードが非常に少なくて済んだということ。今回は、翻訳のエンジンを会話エンジンにするという手法をやってみましたが、改造をしてみるだけでもっと面白いことができるんじゃないか、ということがTensorFlowの良いところではないか」と語りました。
講演後に新村さんに「今後どんなものを作りたいのか」と尋ねてみると、「最終的にはロボットの会話エンジンになるようなものを作りたい」という回答が返ってきました。ロボットの会話機能という点は、一番難しいところでもあり、キラーにもなる可能性を秘めているところなので、是非このまま研究を続けていってもらいたいと思います。新村さんはまだ25歳。この先が非常に楽しみです。
TensorFlowの可能性の一端を知ることができた素晴らしい勉強会でした。



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
望月 亮輔PR







このカテゴリの新着記事





注目のロボット









注目のロボット企業







連載・コラム

