

ボブ・ディランと会話して歌い、レディー・ガガの性格を分析するWatson、その軌跡と全容
今回はまず、IBM Watson(以下、Watsonと表記)と世界的に有名な歌手ボブ・ディラン(Bob Dylan)氏が会話する、30秒のプロモーション映像を紹介します。
Watsonがディラン氏に「言葉を学ぶためにあなたの歌詞をすべて読みました」と話しかけます。まさか、という表情で「僕の曲を? 全部だって?」とディラン氏が問います。するとWatsonが言います。「1秒間に8億ページを読むことができます」。
更にWatsonが分析したディラン氏の歌のテーマがなんであるかを話し、「愛とはなんでしょう?」と問いかけます。さてディラン氏はなんと答えるでしょうか。
「Watsonとの対話」 ボブ・ディラン + IBM Watson 言葉を学ぶ
Watsonが1秒間に読み込めるデータ量はなんと8億ページ。人間にはとうてい真似ができない能力です。更にWatsonは人間のために書かれた文章を理解し、データとして蓄積していくことができます。コンピュータと人間が自然に会話する社会、コンピュータが人間の判断を会話で手助けしてくれる社会がやってきます。
米IBMは2016年1月、「Pepper」向けのIBM Watsonを開発し、世界の企業に提供する計画をソフトバンクロボティクスと共同で発表しました。そのニュースも大変気になりますが、Watson日本語版の発表がいよいよ間近に迫っていますので、Watsonの変遷と日本語版の最新動向を含めて調べました。日本アイビーエムでIBM Watsonのマーケティングマネージャーをつとめる中野氏に聞きます。

神崎(編集部)
Watsonの特長を改めて教えていただけますか
中野(敬称略)
パソコンやサーバを使ってコンピュータが処理した様々なデータを利用している皆さんも多いと思いますが、一般のリレーショナル・データベースではコンピュータが理解したり計算・分類しやすい構造化されたデータが利用されています。わかりやすく言えば、スプレッドシートやデータベースなどのデータです。では、パソコンの中に保存されている構造化されたファイルは全体の何割くらいあるか想像したことがあるでしょうか。
一般的なドキュメントファイル、プレゼンテーション、電子メール、デジタルカメラの写真や録音された音声ファイルなど、人間は読み聞きして理解はできるけれど、一般のコンピュータには理解できない非構造化データが多くを占めているのが実状ではないでしょうか。
ある調査では世界中で蓄積されているビッグデータは、2020年までに44ゼタバイト位になると言われています。
神崎
ゼタバイトですか(笑)。いまはせいぜいハードディスクのテラバイトくらいの単位が一般的ですね。ゼタはテラに比べると・・
中野
テラの上がペタ、その上がゼタですね。44ゼタバイトは440億テラバイトです。1テラバイトのハードディスク440億個分です。しかも、そのビッグデータのほとんどは文章、音声、画像、センサーデバイスなどから蓄積されたデータで、80%以上が構造化されていないデータだと言われています。構造化されていないデータはコンピュータが理解できないと言われてきました。
今、こうして神崎さんはWatsonの取材をして、その内容を記事にしますが、その記事を読まないとヒトは内容が理解できない、人間の場合も同じですよね。コンピュータの場合は一般に人間用に書かれた文章がそもそも理解できないという課題も抱えているのです。
そのため、ビッグデータの蓄積がどんどんと増えていっても、読んでいない、もしくは読めないデータがどんどん蓄積されていったのでは活用されていないに等しいというわけです。
神崎
それを理解し、活用できるのがWatsonということですね。前回、ソフトバンクさんにも聞いたのですが、どうしてWatsonを人工知能と呼ばないのでしょうか?
中野
「人工知能とは何か?」という話も、実はかなりあいまいに捉えられたまま話がされることが多く感じます。
広義では、学習・推論・判断などの人間の知能、または人間の思考、あるいは人格的なものも含めて、人工的な環境で実現する、例えばコンピュータに実装する、あるいはその一部分を切り出して特化した機能をコンピュータ化するというものです。たとえば、チェスや将棋、囲碁で人間に勝つ、あるいは車の自動運転を行うなど、単機能として切り出して実現したものを確かに人工知能と呼ばれることがあります。
しかし、狭義の意味では人工知能≒ディープラーニング(深層学習)、もしくはマシンラーニング(機械学習)であるという論調があって、これらはひとつの機能、ファンクションやテクノロジーとして取り上げられています。Watsonもディープラーニング等の最新テクノロジーを使っていますが、それだけではなくて他にも、30以上の機能をAPIとして公開しています。そこには50以上のテクノロジーが融合されたカタチで使われています。ディープラーニングはそのうちのひとつに過ぎませんので「ディープラーニング≒人工知能、だからWatsonは人工知能でしょ?」と聞かれれば違います、と回答しています。
※「≒」はニアリー・イコール(≈)。ほぼ同じの意。
Watson 5年間の進化の歩み
神崎
Watsonの進化や製品群の全容について教えてください
中野
米国のクイズ番組「Jeopardy!」でクイズ王と対戦してから約5年が経過しています。クイズでの対戦のときのWatsonは実験や研究の段階でした。その半年後にWatsonの商用化を開始するといろいろな企業や組織がこのテクノロジーに興味を持ってくれました。
例えば米ウェルポイント社(WellPoint)からは医療分野で活用できないかということで一緒にプロジェクトを行いました。

米WellPoint社と米IBMが、Watsonを医療分野で応用することに合意したニュースは当時のプレスリリース日本語版でも詳しく報じられています。
Watsonは、
自然言語で問われた質問に対し、素早く正確に、確信度付きで解答する点で、人間の能力に匹敵するコンピューター・システムの構築、という壮大な課題に挑むべくIBMの研究員が開発したものです。
と紹介され、その能力の片鱗が以下のように綴られています。
近年、医療分野は他分野に比べて急速に成長しました。医師にとって、何十万件もの医学文献を診察に活用するのは非常に困難です。Watsonは書籍約100万冊(概ね約2億ページ分)に相当するデータをより分け、情報を解析し、3秒以内に正確な分析結果を導き出すことができます。WellPointは、この驚異的な能力を活用することで、医師たちが個々の患者に応じてWatsonに読み込ませた医療データを参照し、困難な疾患であっても、最も確信度の高い診断や最適な治療法を特定するのに役立てたいと考えています。Watsonは、医療現場での意思決定プロセスにおける強力なツールとなると期待されています。
中野
文献や論文、医療情報、カルテなどの膨大な情報をWatsonに学習させ、患者さんの症状を言うと症状の原因を推論出てて提示したり これらの症状だとこの病気である可能性が高いことを確度の高い順にリストしたり、更には「糖尿病と診断されたことがあるか?」「 親族がかかった病歴は」などWatsonからの質問に回答を加えることで別の病気である可能性も探させたり、こうした情報を元により正確な診断結果を導き出そうというシステムです。
これらの提携プロジェクトをいくつか行ううちに、企業によるWatson利用の想定パターンが見えてきました。
そこでまず、「IBM Watson Engagement Advisor」をリリースしました。顧客対応、人間とのインタラクションが発生するやりとり、質問に対して答えを返すしくみを提供するソリューションです。解りやすく言えば「Q&A」「質疑応答システム」です。
神崎
顧客対応の「IBM Watson Engagement Advisor」を発表した次は、開発者向けの「IBM Watson Developers Cloud」ですね
中野
Watsonはいわゆるエンジンとしてクラウド上に存在します。IBMが Watsonのビジネスを広げていく際、単にエンジンだけを提供すれば良いというわけではなく、そこにアクセスするための 「API (Application Programming Interface)」を提供することが求められるようになってきました。
このようなニーズに対応するため、「IBM Watson Developers Cloud」というPlatformが提供されており、現在 Watsonサービスを利用するために30以上のAPIが公開されており、技術情報やサンプルコード、デモなどを提供しています。
開発者は、IBMの 「PaaS (Platform as a Service)」である「Bluemix」という開発環境から、これらの APIを組み合わせることで、コグニティブなアプリケーションを誰でも簡単に作成することができます。「Bluemix」(ブルーミックス)は既に全世界で約8万人の開発者に利用されています。
Watsonを創薬に活用し、新たな知見や発見を生み出す
「IBM Watson Discovery Advisor」によって創造的な発見が実現しました。医療や創薬の分野には膨大な量の文献や治験データがありますが、日々追加されるデータ量を考えるととても人間では読み切れない、ましてや解析しきれないのが実状です。しかし、高速に文書を読むことができるWatsonなら、それを読んで解析することができます。今まで発見されていなかった新しい化合物をみつけたり、新たに薬の副作用を予測するなど、知見や発見を生み出す支援を行っていて、成果を出していると言います。また、がん抑制遺伝子やそれに作用するたんぱく質の研究、新しい治療薬を試す臨床試験で最適な患者のマッチングを支援すること等にも活用されています。
TED Cognitive Computing 【日本語字幕付】
ヘルスケアではAppleとも連携
また、ヘルスケア分野では米IBMはヘルスケアクラウド基盤「Watson Health Cloud」をオープンな環境として構築するとともに、米Apple社等と提携することを発表しています(2015年4月)。AppleはiPhoneなどで利用しているiOS用に「HealthKit」や「ResearchKit」の普及を推進していますが、「Apple Watch」などのウェアラブル端末でヘルスケアのデータを蓄積し、Watsonによって自然言語でヘルスケア情報のやりとりができるようになると期待されています。また、開発者向けにヘルスケアデータを蓄積し、Watsonを活用して解析等が可能なクラウド環境を提供するとしています。
▽ Watson Health Cloud(英語版)のリンク
http://www.ibm.com/smarterplanet/us/en/ibmwatson/health/
Watsonがレシピを提案する「シェフ・ワトソン」
神崎
2014年6月に発表した「Chef Watson」(英語版)は誰もがホームページでWatsonを体験できるもので、とても身近に感じました。
中野
シェフワトソンは、いくつかの食材を指定し、和風、イタリアン、中華料理などの料理方法や、記念日、誕生日等のスタイルを指定すると、Watsonがそれに合わせて料理の提案をして、そのレシピを作ってくれるというウェブサービスです。
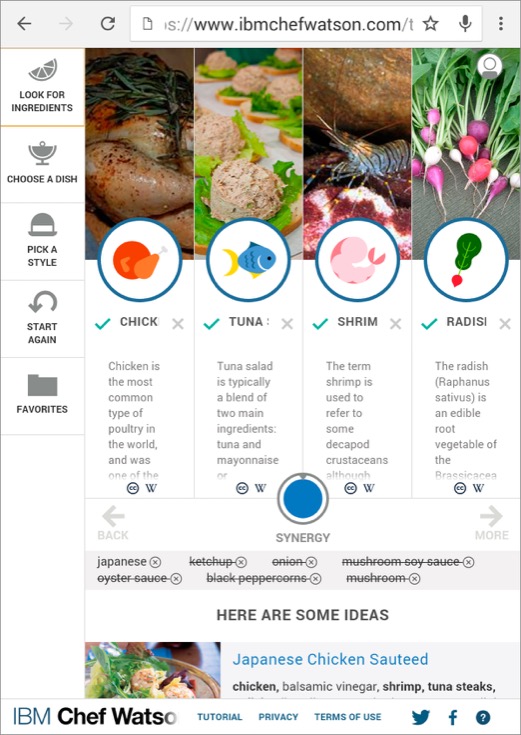
▽ Chef Watsonのリンク
https://www.ibmchefwatson.com/tupler
IBM Cognitive Cooking at L’Effervescence – 未来を味わおう。-
Watsonファミリーの全容
神崎
シェフ・ワトソンはひとつのアプリケーションとして公開されていますね。「5年間の歩み」を見ても、いろいろなWatsonがあります。

中野
Watsonの全容としては「Offering」「Product」「Application」「Platform」に分けられます。
「Offering」(オファーリング)は、ある特定の分野で使うように設計され、定義されたフレームワークというか、料理用、資産管理用など用途を特定した専用のアプリケーションとしてパッケージ化して提供しているものです。
Watson Engagement Advisorは先ほども触れた質疑応答システムです。顧客対応分野で実用化しています。Watson Discovery Advisorは新たな知見を発見するシステムとして創薬やヘルスケアで実用化されています。
「Product」(プロダクト)は従来でいうソフトウェア製品に近いと思っています。
Watson Explorerは日本語化済みで既にソフトウェアとして販売中です。昨年前期にいくつかの銀行がWatsonを導入したというニュースを読んだかもしれませんが、このWatson Explorerが導入されています。
Watson Analyticsはクラウド上の分析ツール、いわゆる「BIツール ※」です。自然言語で問い合わせることができる点が特長のひとつで、バックにはデータベースと繋がっています。例えば売上げのデータベースと繋がっている場合、「先月の売上げは?」と問い合わせるとWatson Analyticsが先月の売上げを集計して回答します。「都道府県別の売上げは?」「あと対前年比も出して」と聞くと、都道府県別に対前年比を集計して回答してくれるというものです。自然言語でやりとりできますが、バックグラウンドで動作しているのはリレーショナルなデータベースです。
※ BIツール Business Intelligence tools、蓄積した膨大な業務データを分析・加工・抽出する意思決定支援ツールのこと
「Application」(アプリケーション)は文字通り、アプリケーションソフトやウェブのサービスとしてリリースされているものです。先のChef Watson、Watson Oncologyはがん治療をサポート、Watson Wealth Managementは個人の資産運用を支援するシステムです。
「Platform」(プラットフォーム)は開発者向けのWatson Developer Cloudと、前述のIBM全般の開発ツール群を提供している「IBM Bluemix」内でWatson関連のツールを提供しているWatson Zone on Bluemix等があります。
▽ IBM Bluemixのリンク
http://www.ibm.com/developerworks/jp/bluemix/
神崎
英語版では既にこれらは全てリリースされているんですね?
それがまもなく日本語版として発表されると・・
中野
英語版はすべてリリースされています。まもなく発表するIBM Watson日本語版は、この中の一部について日本語化が完了した、ということになります。
神崎
日本語化されているものは”日本語が理解できる”と言うことですね?
中野
基本的に現在日本語対応を進めているAPIについては、対応する言語が広がれば複数の言語に同時に対応することが可能です。APIとして呼び出す際に、そこで扱われる言語が「日本語」なのか「英語」なのかを指定することで、1つの APIで複数の言語に対応する、というアプローチです。
もちろん、英語版のWatson APIも利用することはできます。
日本語の対応については、単に Input/Outputの日本語に変換するというだけではなく、日本語の単語、文法を理解し、主語が何で、述語、形容詞などのほか、微妙なニュアンスも含めて「意味」を理解されることが重要になります。
神崎
私も仕事でソフトウェアの画面上の対話を英語から日本語に翻訳する、いわゆるローカライズをしてきた経験がありますが、Watsonの日本語化はそんなレベルとはまったく異なるようですね
中野
そうですね、ローカライズとは全く違います。Watsonのロジックの中に日本語を理解させる、解釈させるロジックを埋め込んで追加していくという作業です。そのため、日本語版を開発すると発表してからここまで約1年が経過していて、やっと一部の日本語版が実現したという膨大な作業です。
神崎
日本語の学習にもディープラーニングは使われるんですか?
中野
文献として日本語で書かれた文章を与えられたそれを読んで意味を理解する、そのコアのテクノロジーのひとつとしてディープラーニングの技術が使われています。

レディー・ガガの性格をWatsonが分析? その結果は?
神崎
シェフ・ワトソンの日本語版があれば、読者の皆さんもWatsonを体験できるのですが、ほかにWatsonの技術を一般のユーザが体験できるサイトはありますか?
中野
IBM Watson Developer CloudではWatsonの技術やツールの情報を紹介していて、デモを体験することができます。
神崎
IBMではAPIやSDKなどの開発ツールを「Bluemix」というサイトで提供していますね。それとは違うのですか?
中野
BluemixではWatson以外にも多数のツール群やAPI等が説明されていてダウンロード提供されていますが、IBM Watson Developer CloudはWatson関連のものをピックアップして紹介しているサイトです。たくさんのデモがあり、紹介しますので見てください。
現時点では、IBM Watson Developer Cloudは日本語化されていません。そのため英語が苦手な方には体験しづらいかもしれませんので、この連載コラムでは中野氏にWatsonのデモをしてもらった内容を解りやすく解説します。
まずは、スーパーボウルで米国国歌を素晴らしい歌声で熱唱した歌手のレディー・ガガさん(以下敬称略)がTwitterでつぶやいている情報をWatsonが検索して解析し、性格を分析するというデモから紹介します。時間があれば実際にやってみてください。
「IBM Watson Developer Cloud」にアクセスしたら、トップページの「See the Service」をクリックします。
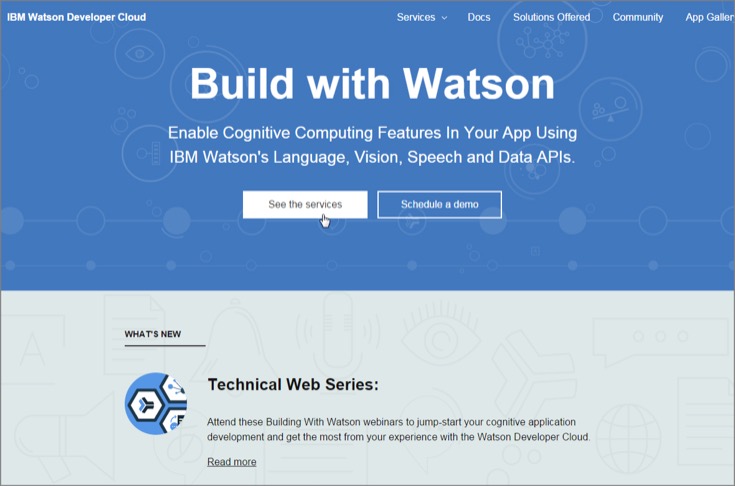
Langage(言語)、Speech(スピーチ)、Vision(画像)、Data Insights(データ分析)の各分野で用意されているWatsonのAPIが一覧できます。これらのAPIは「デモ」で体験してみることができます。
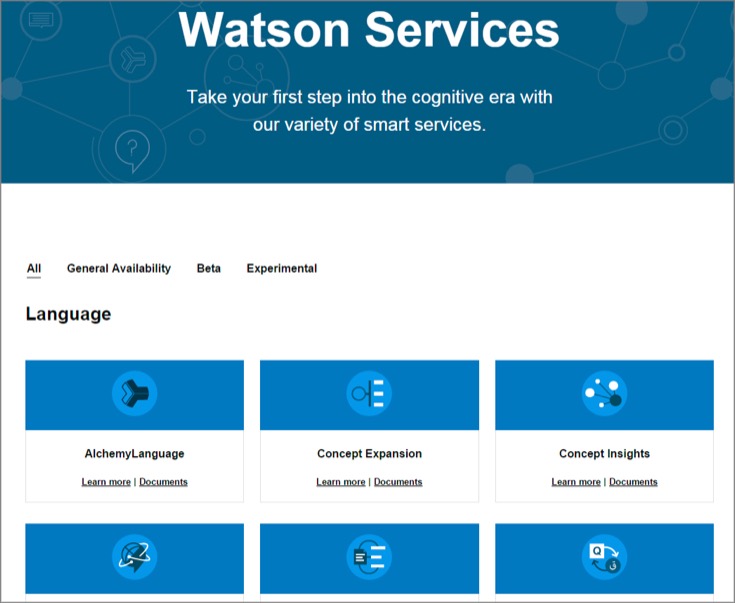
例えば「Language」の中の「Personality Insights」(パーソナリティ分析)の「Learn more」(より詳しく..)をクリックします。
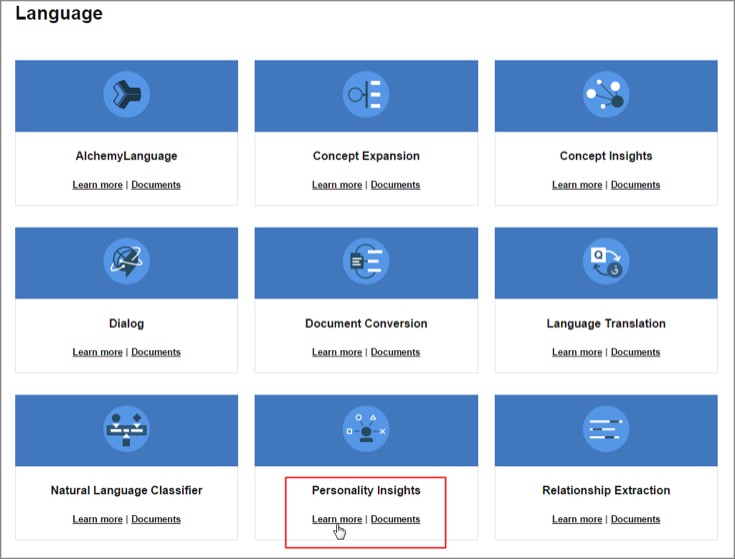
「Personality Insights」の説明が詳しく表示されますが、右下の「View Demo」をクリックすると、実際にどのような動きをするのかというデモが見られます。
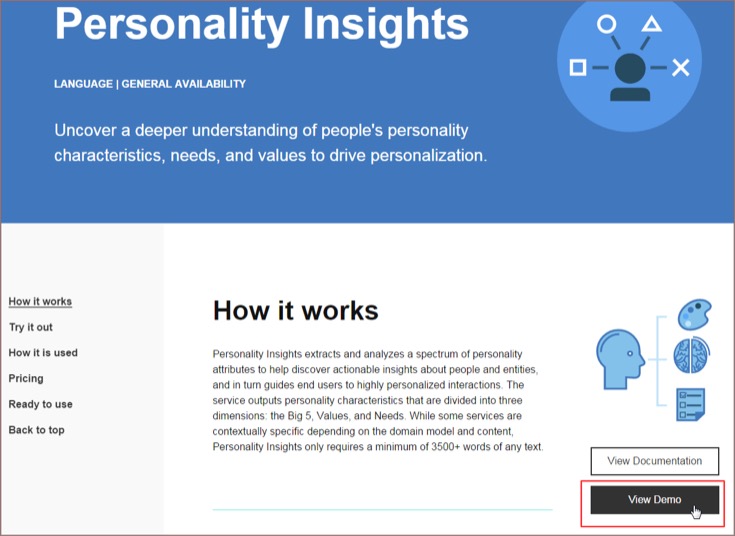
ここでは公開されているTwitterのツイートをWatsonが分析して、そのヒトのパーソナリティ、性格を分析するというものです。画面上にはサンプルとして、オプラ・ウィンフリー(米女優)、レブロン・ジェームズ(米バスケットボール選手)、レディー・ガガ(歌手)のツイッターのアカウントが並んでいます。
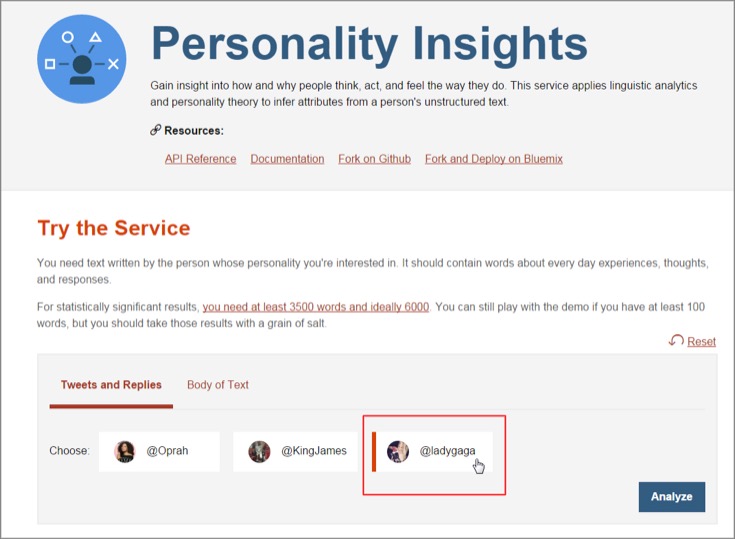
レディー・ガガを選択して「Analyze」をクリックするとレディー・ガガのツイートの分析をWatsonが行い、このヒトはこういう性格でしょう、という推測をしてくれます。レディー・ガガの場合は、14503の単語から性格を解析した結果が表示されます。
性格はアクティブ(積極的)で、美しさや創造的な体験を求めています。
自身に満ちあふれ、困難なことにも取り組むことができます。それでいて達成したことについては比較的無関心。もう少し伝統を重んじて、あなたが所属するグループに対して尊重し、指示に従うことも大切です。
という風なサマリー分析をWatsonが行なっています。
また、「Personality」(性格/個性)「Consumer Needs」(消費者ニーズ)「Values」(価値観)各項目についてパーセンテージで数値化しています。これは心理学の分析手法を使っていて、積極的なのか消極的なのか、新しもの好きかコンサバなのか、怒りやすいのか慎重な人なのか、といった分析を行います。もちろん、この結果は医学的な診断等に使われるべきものではなく、あくまでツイートに基づく、Watsonから見た一般的な推論と分析、ということになります。
例えば、左の列は「Introversion/Extraversion」(内向性/外向性)74%、「Conscientiousness」(誠実さ)73%、「Openness」(開放さ)63%、「Agreeableness」(感じの良さ)61%、「Emotional range」(感情的な範囲)34%となっています。
ここでWatsonが行ったような性格分析の結果をビジネスでどう活用するかというと、顧客の性格や行動を分析した上で、より個人に合わせた(パーソナリティを考慮した)提案が可能になるかもしれません。例えば金融商品であれば、比較的積極的と分析された顧客には多少の危険は伴うけれどハイリスク・ハイリターンの商品を提案し、消極的なヒトにはリスクの少ない堅実な商品を薦めるといった感じです。また、自分中心的な性格と分析されたヒトには「お客様向けに特別な商品」として提案したり、社会性の意識の高いと分析されたヒトには募金に繋がる商品を薦めることもできるでしょう。また、既に一部の企業では導入されていますが、このような技術を人事配置のマッチングやプロジェクトチームのメンバー構成に応用する(Watsonとは別に)システムを構築しているケースもあります。
なお、分析を行うために元となるデータはWatsonを導入するクライアント自身が蓄積する必要があります。前回も触れましたが、Watsonはあらかじめ膨大な量のデータを持っているデータベース・システムではなく、クライアントが蓄積したデータから情報を解析したり、最適解を抽出して決定を支援すること等を行うシステムです。そのため分析するためのデータもクライアントが用意します。ただ、Watsonが他と異なるなのはクライアントが用意するそのデータはデータベースやコンピュータに最適なように構造化されたデータに限らず、人間が読むために作られた文章や音声、画像など非構造化のデータを理解し、学習することができる、ということなのです。
電子メールや文書の内容からトーンを解析
中野氏がデモしたもうひとつのツールは「Tone Analyzer」です。
電子メールや文章ファイル、ブログ、コメントなど様々な文章を読み込んで、そのトーンを解析するツールです。文章のトーンとは、感情的な表現、攻撃的な印象を与える語句、社会的な内容の有無等で、それらをWatsonが分析します。
「デモ」ではプロジェクトチームの管理者(上司)がメンバー(部下)に送ったと想定される電子メールの内容がサンプルになっています。「売上げの状況は厳しい、経済の悪化のせいにはできない」といった少し厳しい内容のメールです。
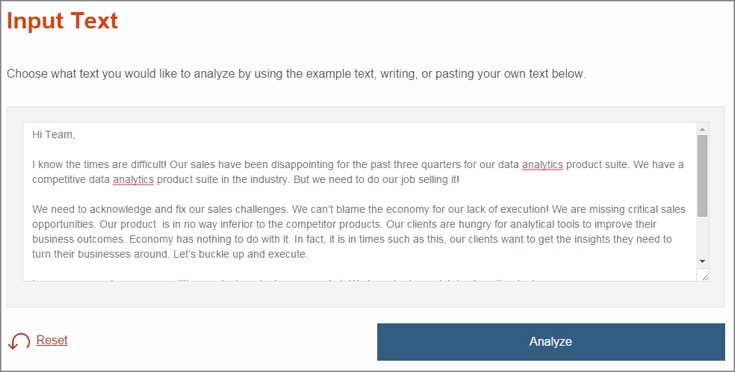
この内容をWatsonが解析して、Anger(怒り)、Cheerfulness(陽気)、Negative(否定的な)、Agreeableness(感じの良い)、Conscientiousness(誠実な)、Openness(開放性)、書き言葉で表現している、などを割合(%)で表示し、どの単語やどの表現からWatsonが判断したか、元になった単語を色分けして表示します。

中野
Watsonの特長のひとつは、質問に対して回答したときにその論拠を示すことができる点です。なぜ、その回答が導き出されたのか、「Tone Analyzer」のデモではWatsonが自然言語の内容を理解できることに加えて、回答の論拠を明示できることがわかる例になっていると思います。
自然言語の解釈が難しいのは、日本語には高度な形態素解析が必要などといったこともありますが、自然言語には「ここ」「それ」「あれ」などの表現が多く、また修飾がどこにかかっているかが解りづらい等が挙げられます。例えば「白い机の上の花」と言った場合、白いのは机なのか、花なのか、ということです。これは一文だけを見ると解りづらいですが、ヒトは会話や文章の流れをつかんで理解しています。Watsonも同様に流れを解釈して理解したり推論することかできます。
Watsonは全知全能なコンピュータではない
中野
誤解のないようにしておきたいのですが「なんでも理解できる全知全能のWatsonがいるのではない」ということです。
自然言語解析のためにWatsonは「コーパス※」を持っています。そのコーパスはクライアントごとにカスタマイズされるもので、それぞれの業界や専門用語、言い回しなどに対応するものです。そこに会話などを加えて学習させていきます。コーパスは例えば、花屋さん業界や家具業界で異なるので「白い机の上の花」の修飾の推論も変わってくるかもしれません。他にも医療業界用、弁護士業界用、コールセンター用などクラウド上にクライアント用のコーパスを設けて運用する構造になっていますが、コールセンターであればどれも同じということではなく、A社のコールセンター用、B社のコールセンター用と、それぞれにカスタマイズされたコーパスが必要なのです。
※コーパス:コンピュータが利用可能な膨大な言語データ。
神崎
Watsonを導入するには赤子から教育していくようなもので、その教育に時間とコストを見込む必要があると聞いていますが、それは最新のWatsonでも同じですか? 例えばですが、花屋さん業界用のワトソンは中学生レベルの花などの知識は持っていて、そこから先の専門的なことを教え込んでいけばいい、というものではないのでしょうか?
中野
ゼロから導入するWatsonは全く何もわかりません。まさに赤ちゃんのような状態です。蓄積されたデータが何もないのでなにを聞いてもわかりません。花屋さん業界用のワトソンが納品されるのではなく、赤ちゃんのWatsonが納品されるという感じです。

中野
最初にも申し上げましたが、ビックデータの活用で最も大きな課題となっているのは、日々蓄積されていくデータをどうやって活用するか、ということです。膨大な量のデータを常に人間がコンピュータが扱うための構造化データに変えていたり、分類していたのでは追いつきませんし、大変なコストがかかります。Watsonでは、ある程度自動的に膨大なデータを読み込ませていけば、どんどん学習して賢くなっていくとともに、分析に活用できるデータを日々蓄積していくことができます。
次回は、日本IBMとソフトバンクによるWatson日本語版の発表と最新情報についてレポートします。お楽しみに。



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
神崎 洋治PR







このカテゴリの新着記事




注目のロボット









注目のロボット企業







連載・コラム

