

このところニューラルネットワークの技術を活用した「会話AIボット」が注目を集めています。「チャットボット」とも呼ばれます。「チャット」とはリアルタイムのコミュニケーションツールのことで、「LINE」やFacebookの「Messenger」などを思い浮かべると解りやすいですね。これらのツールは人と人とのコミュニケーションツールですが、会話AIなどのシステムで対応しようというのがチャットボットです。
日本でもMicrosoftの「りんな」、東京三菱UFJ銀行などがチャットボットでLINEの会話ができるようにしています。
FacebookのCEOマーク・ザッカーバーグ氏は開発者向けイベントの基調講演で、この先10年間で最も注力していく技術に「人工知能(AI)」や「VR/AR」を挙げ、特にAIでは顔認識とチャットボットの分野に注目していることを公言しました。「LINE」では今や、たくさんの企業がアカウントを自社で運営し、ユーザに直接情報を発信するようになってきました。企業のアカウントに友達登録すると、LINEのスタンプが無料でもらえる、会計時に割引価格が適用される等のサービスを理由に友達登録した人も多いと思います。そして一部の企業では既に顧客からの呼びかけにチャットボットが自動で受け応えするサービスを開始しています。FacebookのMessengerでも同様なビジネス展開をAIボットで拡大する計画です。
前回は、機械学習とニューラルネットワークの超基礎となる「特徴量」とその算出の部分を解説しましたが、今回はチャットボットとディープラーニングについて、東京大学発のベンチャー企業「シーエイトラボ」(C8Lab)社のCEO 新村拓也氏に聞き、解りやすい事例をもとに解説します。

会話ゲームとニューラルネットワーク
まずは頭の体操を兼ねて…。
親子の会話遊びのひとつに、あるものを頭に思い浮かべ、それに関連するヒントを言って、相手が答えを推理して当てるゲームがありますよね。例えば、出題者がヒントに「赤い」というと、消防車、郵便ポスト、火、リンゴ、花などが思い浮かびますが、もちろん「赤い」だけでは回答の限定はできません。そこで次のヒントが「フルーツ」であれば、リンゴやイチゴ、さくらんぼなどが思い浮かびます。更に次のヒントが「ヘタに葉っぱがある」「ブツブツがある」と続けば、答えは「イチゴ」だとかなり高い確度でわかります。このヒントを仮に「特徴」と呼ぶことにします。
このゲームをコンピュータ化し、コンピュータが回答するシステムを作ろうと思った場合、赤くて、フルーツに分類されて、ブツブツがあって等の特徴から「イチゴ」という答えを回答するものになります。そのとき「赤い」と「フルーツ」ではまだ曖昧ですが、「ヘタに葉っぱがある」「ブツブツがある」などの多数の特徴があることで正解の確率は上がります。
赤い→ 火、リンゴ、血、花 …
フルーツ→ リンゴ、イチゴ、さくらんぼ …
ヘタに葉っぱがある→ イチゴ
ブツブツがある→ イチゴ きっと間違いない
より正確に回答できるシステムを作りたいと思えば、これらイチゴの特徴をできるだけたくさん登録しておくことが有効です。従来から主に「ルールベース」と呼ばれるしくみではこの特徴を人間が手作業(手入力)でコンピュータに登録していました。
果物だけを対象とした「フルーツ当てクイズ」システムなら、果物の種類がそれほど多くないので、特徴の登録も含めてひとりでもコツコツと登録していける気がします。しかし、子供向けの知育クイズのように、フルーツに限らず、動物、乗り物、家電や雑貨、洋服など身の回りにあるものなど、回答の対象を増やすと、品物や特徴を登録する数が格段に増えて、自分だけで登録するのはなんだか大変そうで、無理な気がしてきます。更に、世の中のあらゆるものを対象にした質疑応答システムを作るとなると、品物も特徴も登録作業はもはや自分ひとりどころか人間の手でやるのは不可能なほど、膨大な情報量に思えてくるでしょう。
そこで思いつきます。
そうだ、機械が自分で特徴をみつけて自分で登録してくれれば楽だぞ…それなら機械任せ、Wikipediaの内容をゴッソリ自動で登録してくれたら便利だし、たちまち賢くなるじゃないか…
ということで機械学習の話です。実際はこの話ほど簡単なことではありませんが、機械学習の凄いところや可能性とはこういうところにあるのです。こうして機械に自律学習してもらうために、兼ねてから研究が進められてきた、人間の脳と同じしくみでコンピュータが学習する方法「ニューラルネットラーク」が登場した、と理解すれば関係性が見えてきます。
ちなみに、「白イチゴ」というものをご存じでしょうか。
Twitterで話題になって注目を集めた、白いイチゴです。Twitterで話題になったとは言え、イチゴやフルーツに興味がなかったり、Twitterを使っていない人はそんなイチゴの存在すら知りません。しかし、もし機械学習がTwitterのデータを収集して自動的に学習するとしたら、コンピュータは「赤いイチゴとは別に白いイチゴがある」ことを理解しているかもしれません。たとえ、開発者が白イチゴを知らなくても。
会話AI・チャットボットのしくみ
神崎(編集部)
新村さんは以前の「TensorFlow勉強会」で、「機械学習だけで会話AIが作れるか?」という実験結果を発表していました。Twitterに投稿されたつぶやきデータをごっそりとクローリングして取ってきて、ディープラーニングのライブラリ「TensorFlow」で組んだ会話AIを使って膨大なつぶやきデータを自動で解析させると、果たしてそれだけをもとにAIは単語を勝手に覚えたり、文章にして人間と会話ができるようになるのか、という面白い発想の試みでしたね。
新村(敬称略)
あれは遊びで作ってみたようなもので(笑)、驚くような結果は得られませんでしたが知見にはなりました。

Twitterの投稿データはいわば膨大な会話データです。必ずしも会話が時系列に並んでいなかったり、使われている単語や言葉が一般のものとは違ったり(日本語を崩した、いわゆる汚い状態)と、いろいろな課題はありますが、膨大な会話の資源だと捉えることもできます。膨大な会話データを形態素解析などの技術を使って単語や文節の解析を行い、前後の単語の関連性や使われ方の傾向を分析して会話AIの基礎データとしていくことも可能です。このデータを読み込ませて解析し続けることで、小さい子供が初めて言葉を学んでいくように、会話ボットが言葉や会話を覚えていくのか? そんな実験でした。
神崎
最近、「チャットボット」が急速に注目を集めていますが、あれはどのようにしくみで会話をしているのでしょうか。「人が教えなくても機械が単語を自分で覚えて、意味や意図を理解する」ということもよく聞きますが、これも具体的にどういうことがおこなわれているのでしょう?
新村
会話AIにはいつくかの手法がありますが、例えば、「マルコフ型」の場合、ある単語の次に来る可能性が高い単語を予測しておき、会話に組み込むことで会話が繋がっているように見える…そんな手法があります。実際にはコンピュータは人間の言葉の意味を理解しているわけではありません。膨大な単語の中から次の単語を予想するために、単語ごとに使われ方の情報を数値化してパラメータとして持っています。
TensorFlowの勉強会で新村氏は、会話AIの代表的な3つの手法を紹介しています。予め用意されたテンプレート辞書に登録された会話を返す「辞書型」、会話履歴にある返答パターンに従って応答する「ログ型」、出現した単語の “次に最も出現しそうな単語” で文章を生成していく「マルコフ型」です。
辞書型
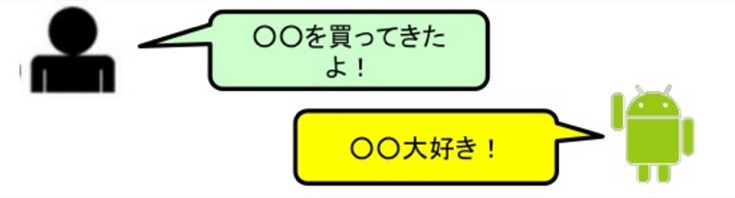
予め用意されたテンプレート辞書に登録された会話を返す方法。例えば、ユーザから何か名詞や固有名詞の単語が発せられたとき、その単語の後ろに「大好き」を繋げて返すといった応答方法です。言われてみると、AIとの会話では実によく見かけます。
ログ型
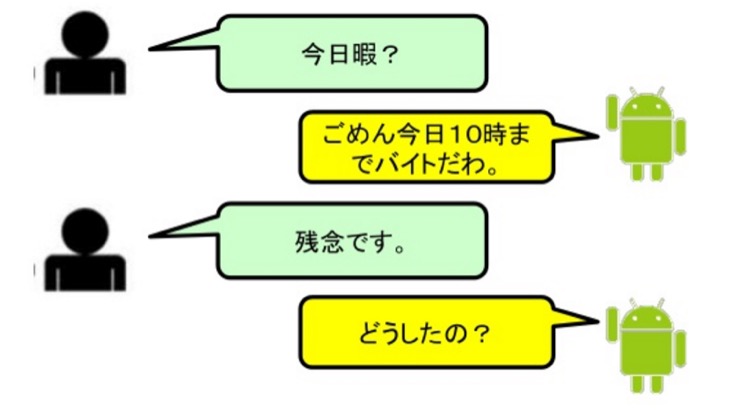
会話履歴にある返答パターンに従って応答する方法。ログ(履歴)、すなわち過去の会話履歴をサンプルデータとして学習します。サンプルの会話として過去にあったものを回答としてそのまま返します。「今夜ヒマですか?」という質問に対して、過去の履歴に同じ質問があって、その回答が「今夜10時まで会議です」だったとしたらそっくりそのまま返したりします。また、「残念です」というフレーズに対して過去に人間が「なにかあったの?」と返信していればそのように返します。実際には文脈は繋がっていませんが、なんとなく会話が繋がっているように感じてしまいます。
マルコフ型
機械: お酒を飲み過ぎました
人間: 二日酔いなの?
機械: 二日酔いの予防は飲酒前が大切なんですよ
「マルコフ型」は会話を解析して単語に分けたとき、その単語の次に来る単語を予測し、確率が高い単語を使って文章を生成するしくみです。もっともAIらしい動きだと言えるかもしれません。回答のパターンやフレーズが多いので、予想外の回答をすることもあります。人間が「お酒は何が好き?」と聞いたとき、過去の履歴には「お酒」の次に「飲み過ぎ」がよく現れることを学習していた場合、「お酒を飲み過ぎました」などと返します。会話としては続いているように思えますが、質問に対する回答にはなっていません。
また、前後の会話を見てみると文脈が通らないことがよくあります(コロコロと話が変わる印象)。上記の例では「二日酔いなの?」という質問に対して、またまた直接回答はせず、二日酔いの予防について解説しています。文脈で見れば、AIの飲み過ぎを心配しているのに、二日酔いを防ぐウンチクを語られている、という流れです。
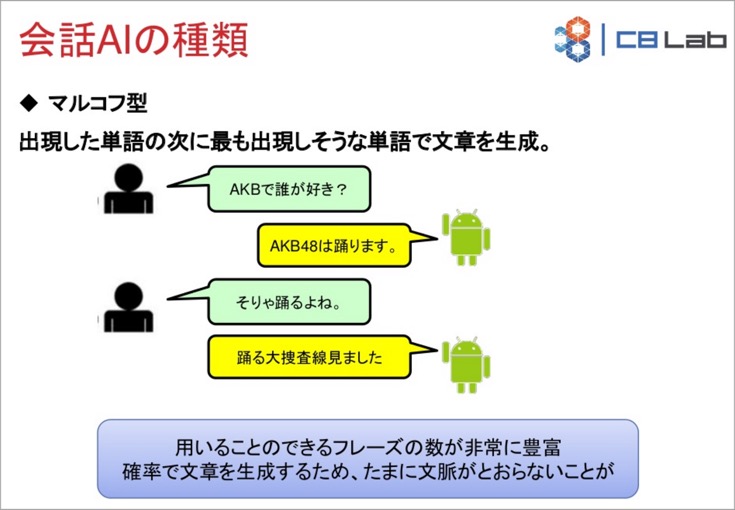
Microsoftの会話AI「りんな」(LINE)をはじめ、いろいろな会話ボットが注目されていますが、実際に使っていると会話の流れがこれらの手法に基づいていることに気付くかもしれません。あたかも意味を持った会話をしているかのようですが、質問に応えていなかったり、上記のスライドのように前後の文脈は通っていないことが多いのです。
単語を「特徴量」づけることはゲームのステータスのようなもの
新村
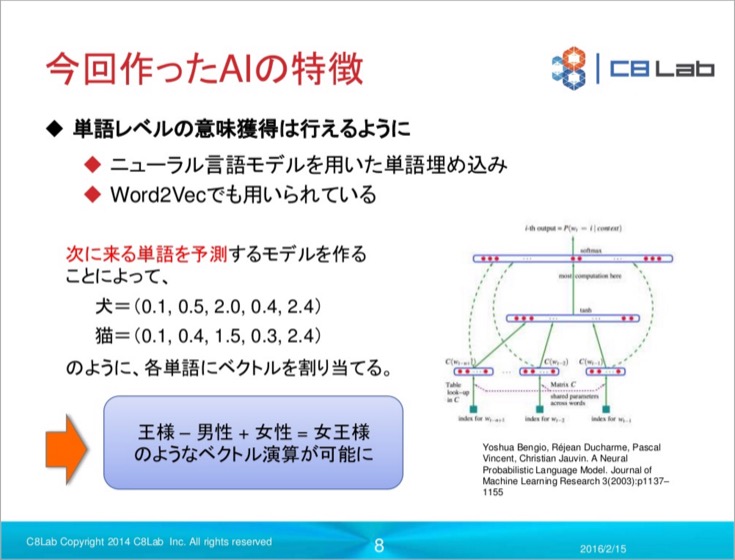
「Word2Vec」というライブラリが公開されていたので今回はこれを使ってみました。Word Embeddingという手法も用いて、「単語」を「ベクトル化」すると単語の類似度や関係性が数値化できるのかな、と考えました。これを特徴量にしますが、この時の特徴量とはゲームで各キャラの特徴を示す「ステータス」のように数で表される値だと考えると良いかもしれません。
神崎
会話でもやはり「特徴量」が重要なんですね。特徴量ではわかりにくいですが、「ステータス」というと想像しやすいかもしれません。
新村
そうですね。ステータスはもっと具体的に言うと、ゲームのHPとか攻撃力とかMPとかの属性数値のイメージです。例えば、Twitterに投稿された膨大のデータを解析すると「犬」と「猫」という単語が見つかります。単語自体は形態素解析等でみつけることができますが、最初はどのように使われる単語かはコンピュータには解りません。
Twitterの膨大な数のつぶやきを集計していくと「犬」や「猫」の話題でつぶやく人は多いんでしょうね、たくさん出て来ます。この「犬」と「猫」の単語の使われ方を解析してステータスで表すとその数値が非常に似たようなものになります。すなわち、「犬」と「猫」の単語は前後に使われる単語が似ているなど、会話の使われ方としてとても似ていることが学習できるわけです。
犬と猫の具体的なステータス(実際に機械が算出した特徴量、ベクトル値)は下記のスライドを見てもらうと解りますが、なるほどよく似ています。
前回の犬と猫の例は画像認識でしたが、ここでは会話AIの例なので、犬と猫の容姿が似ているということではありません。日常の会話の中で、「犬」と「猫」という単語の使われ方の属性が似ているという分析です。例えば「■を飼っています」「ソファーに■が寝ている」「■がエサを欲しがっている」「ようやく家に着いたら愛■が迎えてくれた」という会話の中の■には犬や猫が入る場合が多く、前後に使われる単語が似ている、場合によってはどちらの単語が入っても違和感がないくらいに使われ方が同じ、という話です。これが「ステータスが似ている」という意味です。
言われてみればそうだ、と思うことでも私達は普段そんなことは意識していませんから、ディープラーニングの分析によって日常会話でも新たな「気づき」を得ることが少なからずあるのです。
また、この例では、コンピュータは「犬」や「猫」がどんなものであるかは理解していませんし、理解する必要もありません。生き物であるとかペットであるとかモフモフしているとか、そんな実態については無頓着です。それでも、データ的に単語や会話での使われ方を学習し、覚えることができます。
有名な例では膨大な会話を解析することで「王様 – 男性 + 女性 = 王女様」という導きが自律的に発見可能になる、「王女様」がどんなものかをコンピュータは理解していないものの、言葉としての使われ方は理解できるということです。
ツイッターの投稿をガバッと収集して機械学習させた結果
では、ツイッターの投稿をガバッと収集してニューラルネットワークに機械学習させると、わずか2~3日でどれくらい会話ができるようになったのでしょうか?
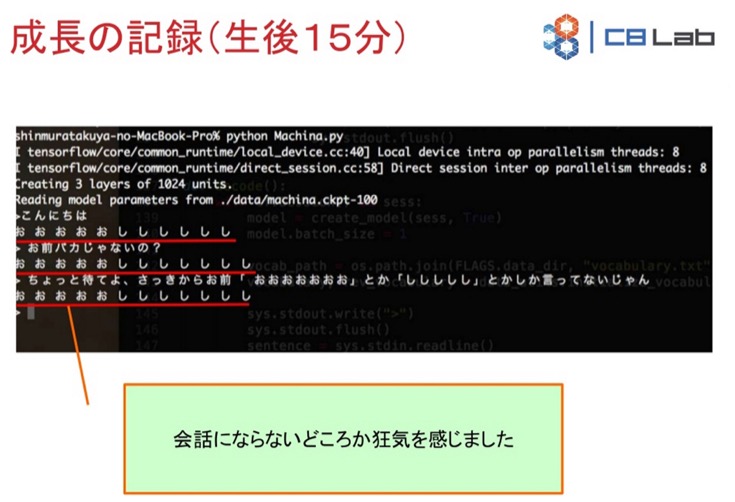
コンピュータが学習しはじめて15分。「こんにちは」という人間の問いかけに「お お お し し し」等と答えてまったく会話になりません(当然ですね、15分ですから)。
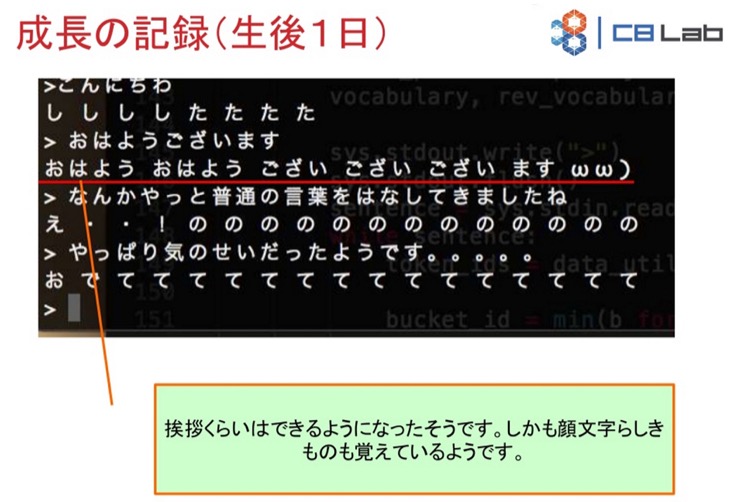
コンピュータが学習しはじめてから1日経過。「おはよう」をかたことで返すようになっています。
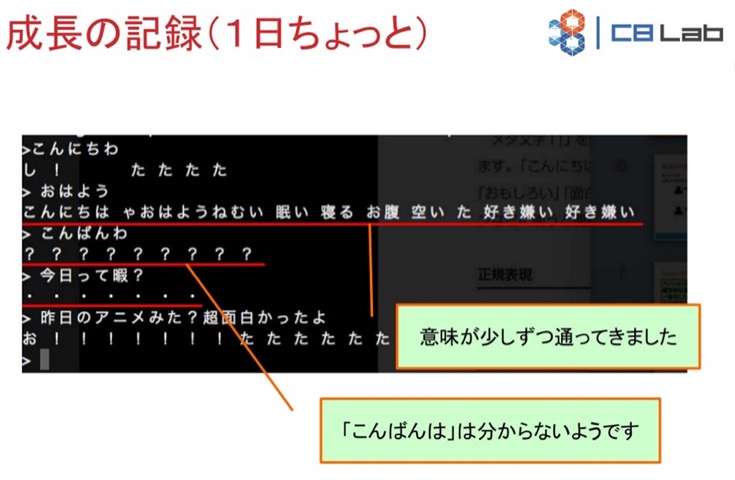
コンピュータが学習しはじめてから1日ちょっと経過。「おはよう」に対して、「眠い」とか「お腹空いた」など、なんとなく返すようになっています。
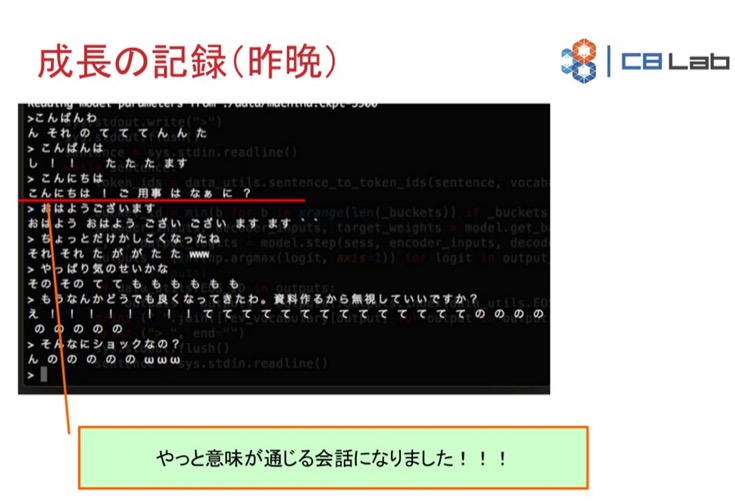
コンピュータが学習しはじめてから3日経過。「こんにちは」という人間の言葉に対して「こんにちは! ご用事はなぁに」と完全ではありませんが、質問で返すようになりました。
勉強会の前日まではここまでの進化。会話とまでは言えないまでも、人間が教えたり、ルールを記述することなく、機械学習だけでかたことの対応までは短期間でもできるように感じます。
なお、勉強会の当日はデモも行われていましたので、その様子は前述のレポートのページをご覧ください。
チャットボットでの人工知能の関連技術の評価は二分
一般的に「チャットボット」の技術が凄いか凄くないかの評価は人それぞれの立場によって分かれています。この「犬」と「猫」、「王様」と「女王様」のくだりを取ってみると、文系の私から見ればとても凄い技術に思えます。しかし、知能研究の立場から見ると会話AIのこの振る舞いは「コンピュータが単語を知的には理解していない」と批判的に捉える見方が多くなる傾向にあります。人工知能と言いながら、実際にはチャットボットは会話の意味はまったく理解していないのですから、「知能」ではないという意見にも納得するところはあります。AIが「人工知能」であるのに対して、チャットボットは「人工無脳」(人工無能)と揶揄されることもあります。
また一方で「単語の使い方を突き詰めていけば、結果的に行間や空気を読んだり、単語を使う場合の会話の意図だって読めるようになるのでは」と好意的に捉えるIT開発者もいます。
人工知能関連技術は、このように立場によって大きく考え方やとらえ方が変わってくるのです。ちなみに今回の新村氏の試みは、チャットボットに少しでも人工知能的な会話AI機能を盛り込みたいという思いもあったそうです。
ディープラーニングを使った即興AIの今後
新村氏自身が「遊びで作った」と言っていましたが、この会話AIには時系列のデータを扱うことに長けた「RNN」(リカレントニューラルネットワーク:ディープラーニングの一種)を使用しています。このAIボットについては残念ながらめざましい成果は残せませんでしたが、今後の課題と可能性を得ることができました。課題としてあげられるのは、収集したTwitterの会話データの数が少なかったこと(ツイート/リプライを含めて約40,000セット)、学習期間が短かったこと、Twitterで使われている会話の言語はクレンジングする必要があること、単語や文節の精度を上げる形態素解析技術の向上、短文データの対話コーパスの生成など、が挙げられました。そして更に「ニューラルネットワークだけでは会話AIを作ることはおそらく不可能なので、それ以外の手法と組み合わせていくべき」とのことです。
一方、良かった点もたくさんあり、TensorFlowはチュートリアルが充実していて、TensorFlowボードと呼ばれるダッシュボード機能がとても使いやすいこと、TensorFlowを使った機械学習のプログラミングはソースコードの量が約500ステップと予想以上に少なかったことなどをあげています。

今回は話題のチャットボット、会話AIについて分析し、ディープラーニングと絡めて解説しましたがどうだったでしょうか。
次回はいよいよ「ディープラーニング」のしくみに迫ります。AI関連の専門用語の意味やしくみを変数や公式が出てこない、文系でも解る解説でご紹介しますので是非ご期待ください。
また、今回のように人工知能の技術をやさしく解説したり、ビジネス活用事例を紹介する本を現在執筆中ですので、そちらも是非ご期待ください。では、次回もお楽しみに。
【追記】発売されました!「図解入門 最新 人工知能がよ〜くわかる本」です。
「人工知能の最新情報とビジネス活用を網羅した書籍「図解入門 最新人工知能がよ~くわかる本」が発売」
東大発ベンチャーC8Labに聞く(3) 「ディープラーニング超入門 多層や畳み込みのしくみ」
東大発ベンチャーC8Labに聞く(2) チャットボットのしくみと会話AI試作と課題
東大発ベンチャーC8Labに聞く(1) 機械学習とニューラルネットワーク超入門



この記事を読んだ人におすすめ
ABOUT THE AUTHOR /
神崎 洋治PR







このカテゴリの新着記事




注目のロボット









注目のロボット企業







連載・コラム

